June 7, 2024
The future of interactive information in Kosmik...

What if we weren’t using apps?
What if our computers were just showing us documents and the appropriate tools to edit them?
This was the vision of Bill Atkinson when he created Hypercard. To create a software that could allow users to mix different data, and to link them together.
Your contacts and your notes about your meetings shouldn’t be in separate apps. Your ideas and their developments should be together because one is growing out of the other. What we need is interactive information.
On interactive information, from Bill Atkinson’s 1988 infoworld interview.
What Hypercard offers is a new format.
On the Mac, you’ve got a document and an application. Documents have information in them; they’re passive. They’re acted upon by the dominant, all-active application, which contains none of the information. So you have passive data and an active application. The data can be created by users, while the applications can only be created by an elite priesthood of authors. Hypercard is a new format operating in between application and document, bounding the two together as interactive information.
Unbundling the browser and apps
This is exactly what will happen with the unbundling of the browser, LLMs and spatial interfaces. Just as we can now clip, remix and repost viral videos, we’ll soon be able to clip, remix or repost parts of a program, website or app.
The ultimate software will be a screenshotting tool with the ability to bring information back to life from an image. Take a screenshot from Photoshop palette, one from Keynote canvas, copy and paste in Preview, and press ▶.

Just as Alan Key predicted, “The main job of the computer will be to learn from the user”.
This is why I continue to be excited by the iPad, despite what amounts (for now) to a lack of vision for iPadOS could be. The iPad remains such a well-positioned device in spite of what Apple has failed to do with it. It can be used at a desktop and extended with a monitor, it can be taken out in the field and used for computer vision. It has a multitouch display yet can be used with a mouse. It can be configured with a SIM card and connected to LTE. The micro computer of the future is still a real possibility.
But the larger question is, what shape will this computer take? The AI craze is already creating a new wave of hardware devices — still largely a work in progress.
When Bill Atkinson started to work on Hypercard (originally Wildcard), he envisioned a pen-activated tablet (like the Macintosh) that would enable the user to mix, remix and create any kind of data with a pen-activated notebook like UI (hence the paper and stack metaphor).

A tablet Macintosh designed by Frog Design in the early 80’s for apple (Snow White design language exploration).
It may seem strange now, but several trends in the 1980s could have shifted personal computing in a very different direction: personal hypertext (HyperCard, Canon CAT, and other software like NoteCards); pen-activated computing and tablets; CD-ROM.
This led Apple to conceive of its own “future vision”, presented at the 1987 EduCom conference. You probably know this concept by its more popular name of “Knowledge Navigator”.
The Knowledge Navigator and us

A wooden mock-up of the knowledge navigator.
The Knowledge Navigator was presented as the future: a computer in which information is manipulated by an agent, always seeking answers and not limiting itself to the confines of your hard drive, but capable of going online to cross-reference and augment its knowledge.
Almost entirely voice-activated and touch-based, the Knowledge Navigator was a remix of the original Dynabook.

In the early 90’s pen-driven UIs and document-oriented systems were still seen as contenders to more classical OS like Windows and MacOS.
But more importantly, within that famous talk at EduCom, John Sculley talks about the significance of artificial intelligence, novel interfaces, and yes, personal hypermedia.
Here’s what Sculley said right before introducing the concept video of the KN:
“But perhaps the most spectacular event will not be the presentation level but lies deeper in the programming. Just a short way into the future, we will see artificial intelligence emerge as a core technology. Combined with other core technologies, AI will boost simulations and hypermedia to new levels of realism and usefulness. We will move, for example, from building molecules in 2 and 3-dimensional spaces to building the environment in which they combine, where each molecule understand the structure and behaviors of the others.”
The search for direct agent manipulation
We couldn’t agree more, but the question is, what is the interface of such a system, now that we’re almost there?
Current AI agents are very "input-output" oriented, just like early micro-computers. You enter a prompt and you get an answer back from the machine. But the real strength of those agents will be to continuously fetch knowledge for you and to present it at the right time.
Last week we talked about our vision for organizational method in Kosmik. One of those method is what we call "seed stacks" — stacks that are seeding information continuously. Let's take a look at how this could work in Kosmik and how it could help you leverage your knowledge base.
A sneak peek at our vision for the Knowledge Navigator
Kosmik already makes it possible to explore the web and create multimedia documents that are interactive. But the next step is about making the canvas proactive.
In the future Kosmik will show you the tags you've applied to an object and also the ones that we think you may want to add.
That's cool, but other apps are already offering auto-tagging systems like this one. What we want to offer with Kosmik is a way to catalog but also explore and enrich your knowledge base.
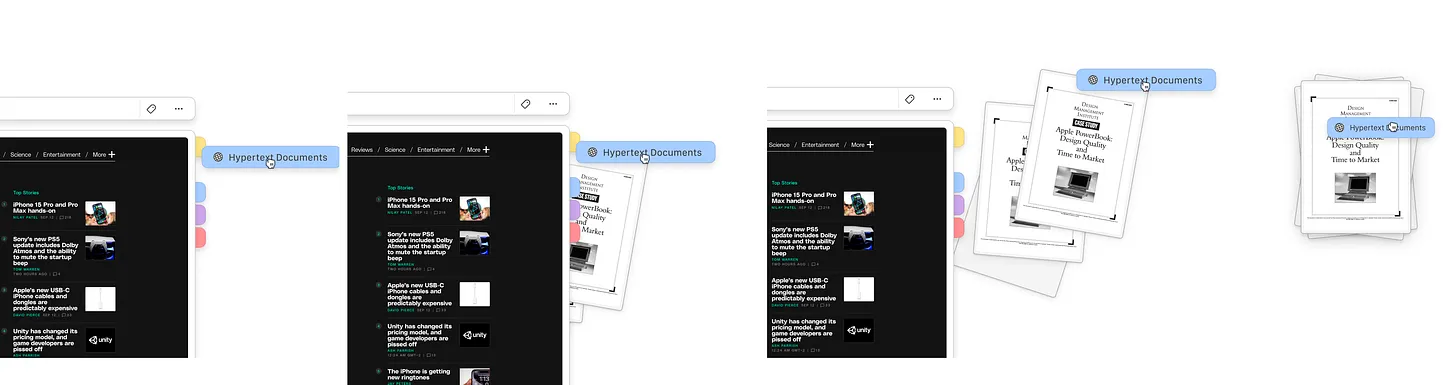
Tabbed tags, pulled tags and seed stacks.
In the example above, the user is doing some research on hypertext.
By pulling on the tab on the right border of the object, Kosmik will create a seed-stack that will continue to self-update as long as data matching those terms is added.
Those seed stacks will be a way for users to combine search and tags in one simple command. They also have the advantage to persist on the canvas, whereas search is usually a non-persistent activity in current systems (like Spotlight for example).

Within stacks of content, the user will also be able to "drill down" and explore a specific topic. Because stacks are not static you can combine information, queries and refine the results quickly.

Our future search UI combined with auto-tags and tabbed tags.
But we want to go a step further!
We think that we can do better than prompting to create a dialogue between you and your knowledge. What we're experimenting with currently is "magic ink". Highlight a part of a text and ask Kosmik to create a stack about the terms you've highlighted.
Highlight part of an image and ask Kosmik to remove it, label it or give you similar images.
This is what interactive information is: the absence of frontier between the content and the tools used to act on it.
We need to create direct manipulation for agents to be effective and for AI to really be useful.
Instead of typing "Tell me more about this author" you should highlight "Melville" with your pencil or mouse and Kosmik will return a "Melville" stack with the proper informations about the author and its bibliographies.
"Seed" the information to the agent and then refine it. You shouldn't prompt, or at least not only prompt. We're not going to displace search with generated answer, we need a something fluid, useful, immediate, fuzzy and expandable.
We're super excited to show you the results of those explorations very soon!
